Tom Turney, Founder & CTO, PsyGuard.AI
Yesterday Google Research published a paper called TurboQuant that compresses LLM memory by 5x with zero accuracy loss. Within hours, I had it running locally. Here's why this matters for PsyGuard.AI and the future of AI-powered qualitative research.
The Problem We're Solving
PsyGuard AI runs AI-simulated focus groups. When a market researcher wants to understand how 12 psychologically-profiled participants would react to a new product, our system generates those participants, runs the discussion, and produces structured, multi-level insights reports, all in 24 hours instead of the weeks and thousands of dollars that traditional focus groups require.
The bottleneck isn’t intelligence. Modern models, when paired with PsyGuard’s proprietary architecture, are already remarkably good at simulating nuanced human behavior. The bottleneck is context.
Every focus group study requires the model to hold in memory: the rich, psychologically grounded participant profiles, the entire discussion transcript so far, the research objectives, and the accumulated context from previous questions. For a typical study with multiple participants and a structured discussion guide, that’s a lot of memory.
When that memory fills up, the model either loses track of earlier context (participants "forget" what they said), or inference slows to a crawl as the system reprocesses everything. This directly impacts the quality and speed of our reports.
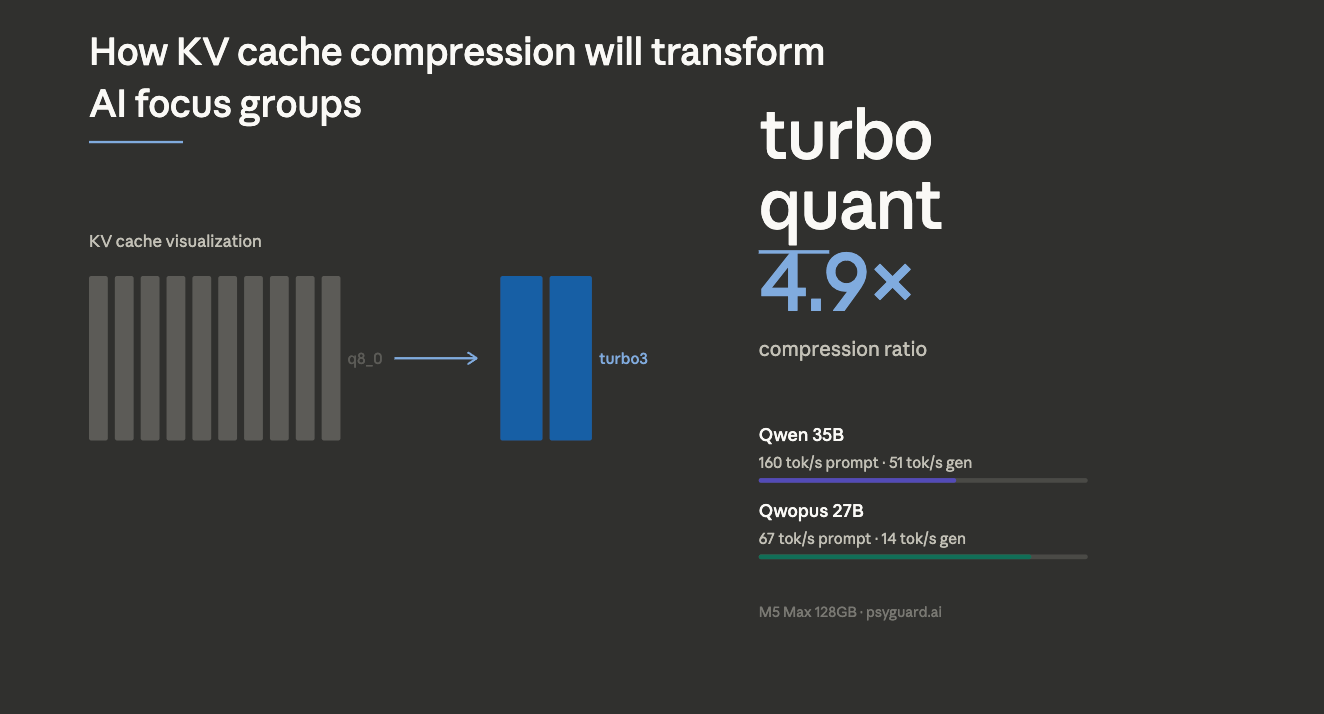
What TurboQuant Changes
TurboQuant compresses the model's working memory (called the KV cache) by nearly 5x using a mathematically elegant approach: randomly rotate the memory vectors so their coordinates become perfectly Gaussian, then apply optimal scalar quantization. The result is the same information stored in 3 bits instead of 16.
I validated this on real model data. The raw memory values have a statistical kurtosis of 900 (extremely uneven distribution). After the rotation, kurtosis drops to 2.9. A perfect Gaussian is 3.0. The math is exact to six decimal places.
What this means practically: models that previously hit context limits can now handle roughly 5× more information on the same hardware. In our case, that’s the difference between shallow, constrained discussions and fully developed simulations with richer participant profiles and longer, more coherent conversations.
The Speed Story
Compression is only useful if it doesn’t come at the cost of speed. The initial implementation was significantly slower, making it impractical. After optimization (identifying a key performance bottleneck and removing unnecessary work from the critical path), performance improved substantially:
- 60% of baseline speed on a Mixture-of-Experts model (51 tok/s vs 85 tok/s)
- 83% of baseline speed on a dense model (14.6 tok/s vs 17.6 tok/s)
The dense model result is the most relevant for our use case. Our insights pipeline operates across multiple layers that build on each other, so a modest reduction in speed is far less impactful than losing context mid-analysis. And with further testing and optimization, we expect this gap to continue narrowing.
Implications for PsyGuard Focus Groups
Richer Participant Profiles
With 5x more context budget, we can give each simulated participant deeper psychological profiles. More life events, more nuanced personality traits, more detailed communication patterns. The AI doesn't have to compress or forget personality details as the discussion progresses.
Longer, More Natural Discussions
Traditional focus groups run 60-90 minutes with 8-10 questions. Ours are limited by context window, not clock time. With compressed KV cache, we can run significantly longer discussions where later questions build meaningfully on earlier responses, something that breaks down when the model loses early context.
Better Insights Quality
Our insights pipeline operates across multiple layers that build on the full discussion context. When more context is preserved, later stages can work with a more complete picture, resulting in clearer and more coherent strategic recommendations.
Path to Local Inference
This is where this goes. Today, most AI systems depend on external inference infrastructure, where each request comes with cost, data overhead, and externally imposed guardrails. KV cache compression changes that equation, making long-context inference feasible on local infrastructure, either on our own systems or eventually on customer hardware.
A model that previously required over 100GB of memory for long-context workloads can now run in the 25–30GB range, putting it within reach of a single GPU or even a high-end laptop. Combined with open-source models rapidly approaching API-level quality (Qwen 3.5, the model I tested TurboQuant on, is already competitive for many tasks), the path to fully local, private AI focus groups is now within reach.
What's Next
The TurboQuant implementation is open source (github.com/TheTom/turboquant_plus). We're working on additional optimizations beyond the original paper: adaptive bit allocation that gives recent context higher precision, and layer-specific compression that matches each part of the model's attention patterns.
For PsyGuard customers, the near-term impact is better report quality from longer context windows. The medium-term impact is lower inference costs. The long-term impact is the option to run entirely on-premise for organizations that need it.
The paper dropped yesterday morning. By last night it was running on my laptop, producing coherent text with 5x less memory. That's the pace AI infrastructure is moving at. We’re building PsyGuard for where that curve is going, not where it’s been.
PsyGuard AI offers AI-powered virtual focus groups at 80%+ less cost than traditional methods, with 24-hour turnaround. Learn more at psyguard.ai